Common Crawl AWS Infrastructure Status
Overall Status
(July 15, 2025)
Performance has been consistently good since the July 4 incident was mitigated.
Please see below for the details of maximizing download speeds.
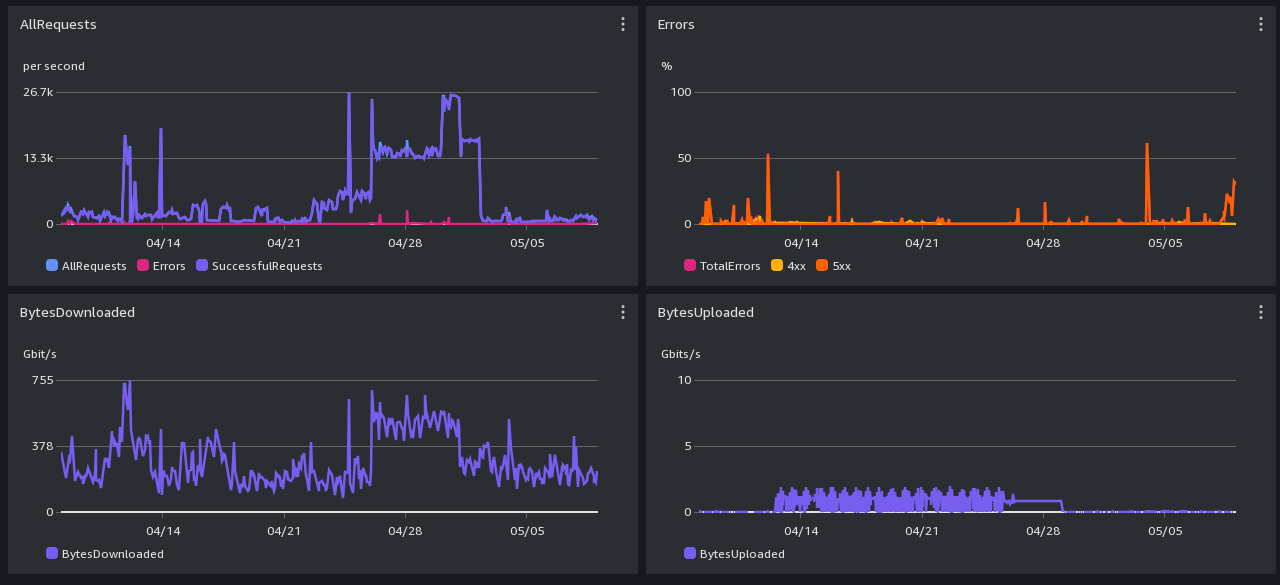
CloudFront (https) Performance Screenshot -- past week
Graph-reading hints: We can handle a few thousand requests per second, not millions.
All times are in UTC. Scroll down for daily and monthly screenshots.
CloudFront: 4xx errors are mostly Greg's explicit rate limit rules. It is normal for there to be a lot of 4xx
caused by users who aren't slowing down when asked.
Cloudfront 503s come from S3 backpressure.
S3: 503 errors are backpressure, dunno what 4xx errors are.
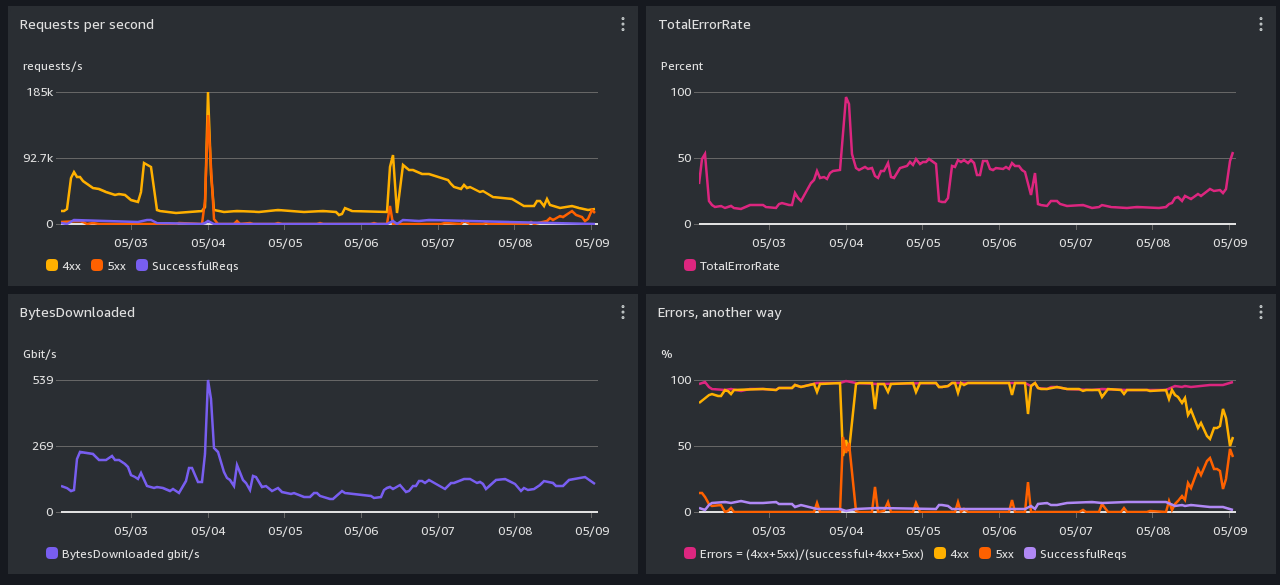
s3:// Performance Screenshot -- past week
Details
Starting in October 2023, extremely aggressive downloaders have been causing high traffic to our AWS-hosted open data bucket. The main symptom users will see are “503 Slow Down” errors when accessing our bucket. Once the bucket is temporarily overwhelmed, it sends these 503 errors to everyone, including users sending even a single request.
We worked with AWS’s S3 and network teams to mitigate these issues, and in November 2023 we deployed rate limiting. Since then, performance problems have only occasionally happened.
The following workarounds might be helpful for downloading whole files from our dataset, even when we’re experiencing a log of 503s:
Using Common Crawl (outside AWS) using the official client
We have an official downloader client at https://github.com/commoncrawl/cc-downloader which can be installed via Cargo with the following command:
cargo install cc-downloader
Please see the cc-downloader github repo for more documentation.
Using Common Crawl (outside AWS) over HTTPS
For bulk downloads, such as whole files, it’s possible to work around these 503s by politely retrying many times. Retrying no more than once per second is polite enough. And once you are lucky and get a request through, you’ll get the entire file without any further rate limit checks.
Here are some recipes for enabling retries for popular command-line tools:
curl: 1 second retries, and download filename taken from URL
curl -O --retry 1000 --retry-all-errors --retry-delay 1 https://data.commoncrawl.org/...
wget: 1 second retries
wget -c -t 0 --retry-on-http-error=503 --waitretry=1 https://data.commoncrawl.org/...
This retry technique does not work well enough for partial file downloads, such as index lookups and downloading individual webpage captures from within a WARC file.
Using Common Crawl (inside AWS) via an S3 client
As you can see in the various graphs, in general inside-AWS S3 usage is working better than usage via CloudFront (https). However, most S3 clients tend to split large downloads into many separate requests, and this makes them more vulnerable to the entire download failing after too many retries.
This configuration turns single file downloads into a single transaction:
$ cat ~/.aws/config
[default]
region = us-east-1
retry_mode = adaptive
max_attempts = 100000
s3 =
multipart_threshold=3GB
multipart_chunksize=3GB
Using Amazon Athena to access the Columnar Index
Amazon Athena makes many small requests over S3 as it does its work. Unfortunately, it does not try very hard to retry 503 problems, and we have been unable to figure out a configuration for Athena that improves its retries. If you simply run a failed transaction a second time, you’ll get billed again and it probably also won’t succeed.
We use Amazon Athena queries ourselves as part of our crawling configuration. Because we make a lot of queries, we downloaded the parquet columnar index files for the past few crawls and used DuckDB to run SQL queries against them. In Python, starting DuckDB and running a query looks like this:
import duckdb, glob
files = glob.glob('/home/cc-pds/bucket-mirror/cc-index/table/cc-main/warc/crawl=*/subset=*/*.parquet')
ccindex = duckdb.read_parquet(files, hive_partitioning=True)
duckdb.sql('SELECT COUNT(*) FROM ccindex;')
Status history
(July 4, 2025)
Starting UTC 17:34, “someone” started attempting to make 100,000 requests per second from our AWS Cloudfront website at https://data.commoncrawl.org/ – we can only sustain a few thousand requests per second combined for everyone who wishes to use Common Crawl’s dataset. This caused distress at both the Cloudfront level, but also at the S3 level, which hurts inside-AWS users and our cdx index server. It also put our crawler at risk for crashing – luckily it appears that improvements we made months ago to improve error handling in our crawler actually worked under stress.
AWS only shows us a limited amount of information about requests. We could see that they were coming from inside the US, and they were all range requests – the kind of thing you’d do if you were trying to download a subset of Common Crawl, such as webpages in a particular language. We appreciate this kind of use, but if you want to do this, you can’t send us 100,000 requests per second. Also, when you access our data, you shouldn’t ignore 4xx or 5xx error codes – when you see anything unusual, you should slow down. And if you’re receiving 98% 4xx or 5xx codes, maybe you should rethink how fast you’re attempting to download.
At UTC 21:92 we started blocking the particular user-agent used by “someone”, also sending a response body that indicated how to contact us. This was effective in blocking the remaining 2% of “someone’s” traffic, but wasn’t enough for our Cloudfront endpoint and S3 bucket to recover.
A user-agent block is trivial to work around, but our hope was that “someone” would think of contacting us.
At UTC 22:34, “someone” reduced their request rate to 7,000 per second, all with the same user-agent, so they were still blocked.
We’ll continue monitoring throughout the holiday weekend.
(March 22, 2025) Updated instructions to include the new cc-downloader client.
(May 12, 2024) Updated instructions for AWS S3 configuration to mitigate 503 “Slow Down” problems.
(Nov 27, 2023) After the US holiday weekend, starting with the European morning, our aggressive downloaders have returned. Rate limiting is mostly taking care of the problem.
(Nov 22, 2023) Yesterday at 15:17 UTC we deployed rate limiting for CloudFront (https) accesses. This appears to have significantly improved the fairness of request handling, with very aggressive downloaders receiving errors and more gentle usage only occasionally seeing errors.
(Nov 17, 2023) Amazon has increased our resource quota.
(Nov 15, 2023) Very high request rates and aggressive retries from a small number of users are causing many 503 “Slow Down” replies to almost all S3 and CloudFront (https://data.commoncrawl.org/) requests. This has been causing problems for all users during the months of October and November.
Please see below for some hints for how to responsibly retry your downloads.
(Nov 14, 2023) New status page
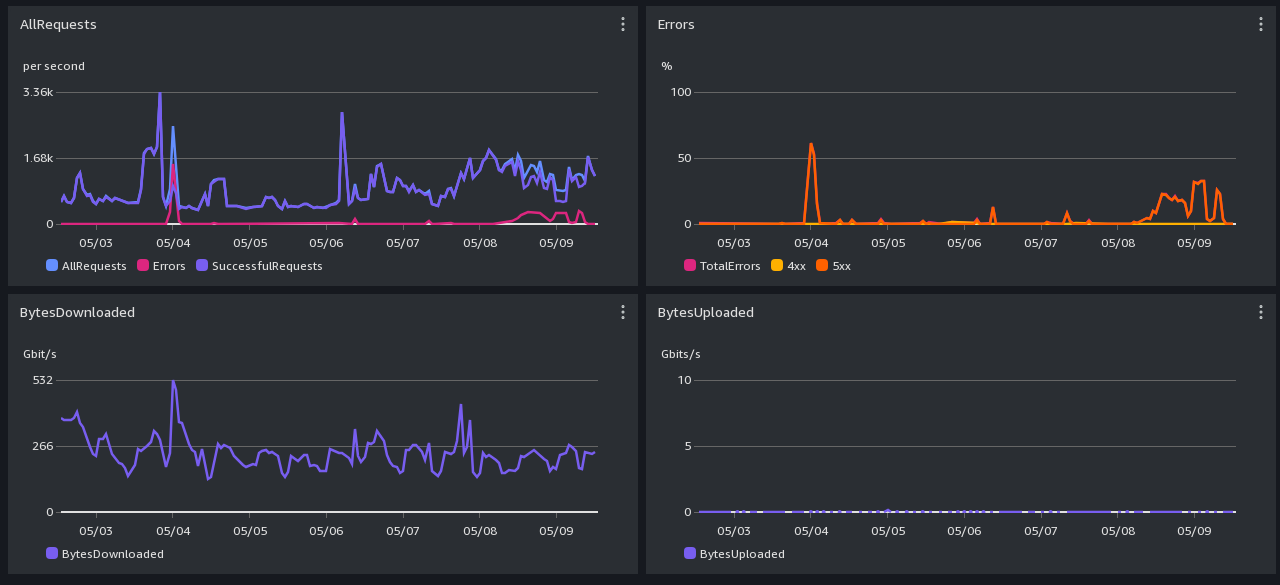
CloudFront (https) Performance Screenshot -- past day
Graph-reading hints: We can handle a few thousand requests per second, not millions.
All times are in UTC. Scroll down for daily and monthly screenshots.
CloudFront: 4xx errors are mostly Greg's explicit rate limit rules. It is normal for there to be a lot of 4xx
caused by users who aren't slowing down when asked.
Cloudfront 503s come from S3 backpressure.
S3: 503 errors are backpressure, dunno what 4xx errors are.
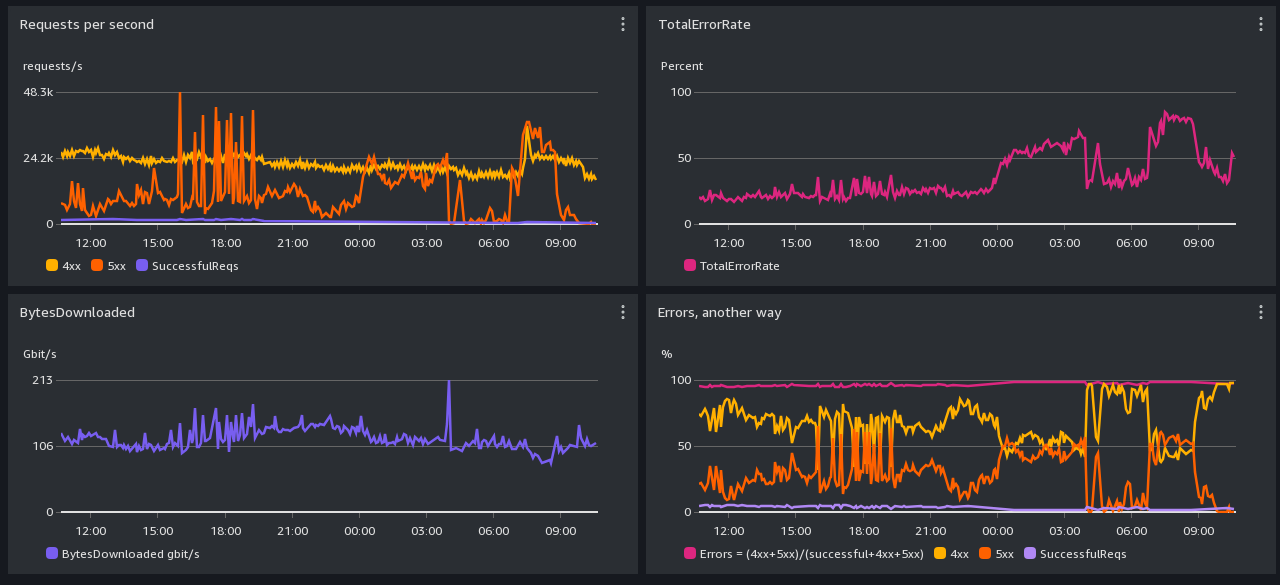
s3:// Performance Screenshot -- past day
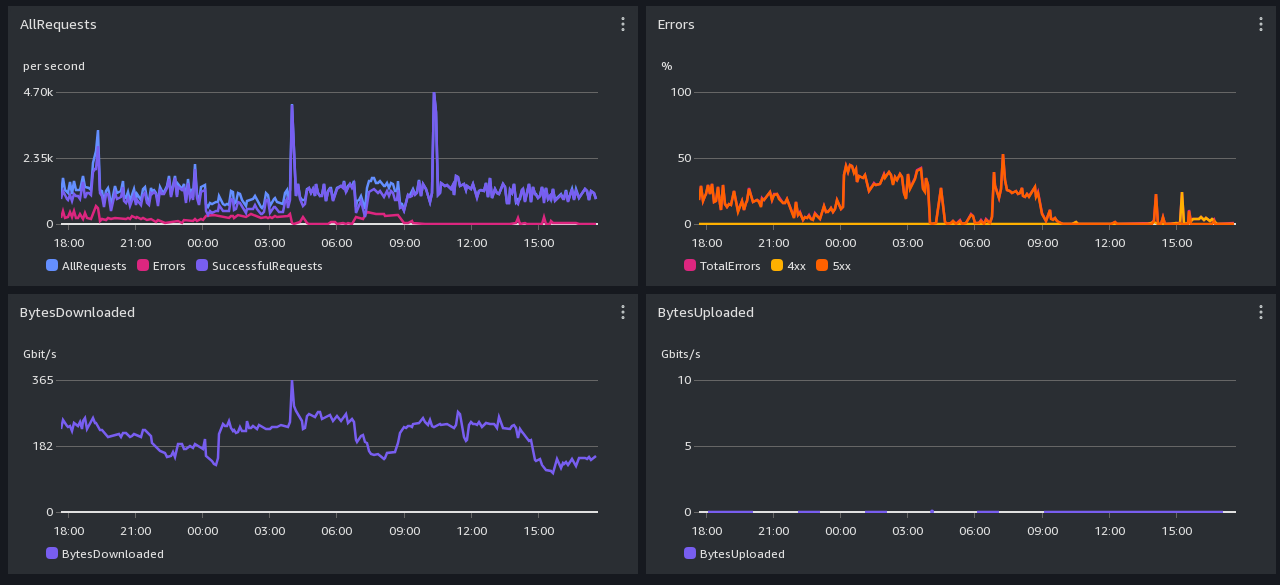
CloudFront (https) Performance Screenshot -- past month
Graph-reading hints: We can handle a few thousand requests per second, not millions.
All times are in UTC. Scroll down for daily and monthly screenshots.
CloudFront: 4xx errors are mostly Greg's explicit rate limit rules. It is normal for there to be a lot of 4xx
caused by users who aren't slowing down when asked.
Cloudfront 503s come from S3 backpressure.
S3: 503 errors are backpressure, dunno what 4xx errors are.
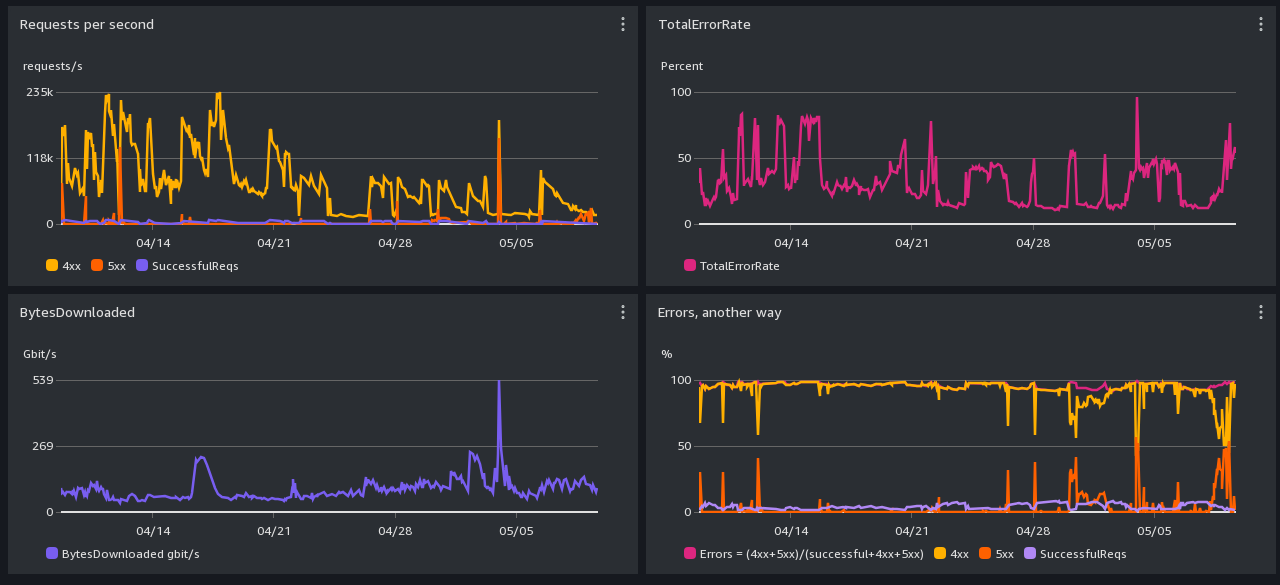
s3:// Performance Screenshot -- past month